




Introduction
In today's high-traffic database management systems (DBMS), leveraging the full potential of hardware is essential. With the advent of modern CPUs, the opportunity for parallel processing has increased significantly. However, executing multiple transactions simultaneously can result in data inconsistencies without proper concurrency control. This is why implementing effective concurrency control is crucial in ensuring the accuracy and reliability of data in a multi-user environment.
A practical method for concurrency control in database management systems is to adopt a pessimistic approach. This approach assumes that conflicts will occur frequently when multiple transactions run simultaneously, and therefore requires transactions to obtain locks on shared data before accessing or modifying it. The system can ensure that data consistency and integrity are maintained, even in a high-traffic environment.
Two-Phase Locking
Why?
Using locks doesn't guarantee the serializability of transactions, consider this example:
T1 | T2
BEGIN |
X-LOCK(A) |
R(A) |
W(A) |
UNLOCK(A) |
| BEGIN
| X-LOCK(A)
| W(A)
| UNLOCK(A)
S-LOCK(A) |
R(A) |
UNLOCK(A) |
COMMIT | COMMIT
Note: X-LOCK() means exclusive lock, used for writes, and S-LOCK() means shared lock, used for reading without blocking other transactions reading at the same time.
As we can see, using locks doesn't prevent T1 from reading a dirty value for A, as T2 didn't commit before the second R(A) in T1, so we exposed a value that wouldn't have been if we run in serializable order.
Also, using locks in a random way can increase the chances of having a deadlock in the system.
How?
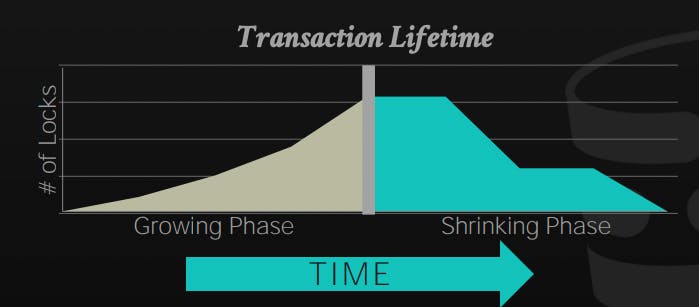
It's not surprising to know that Two-Phase locking is constructed by two phases:
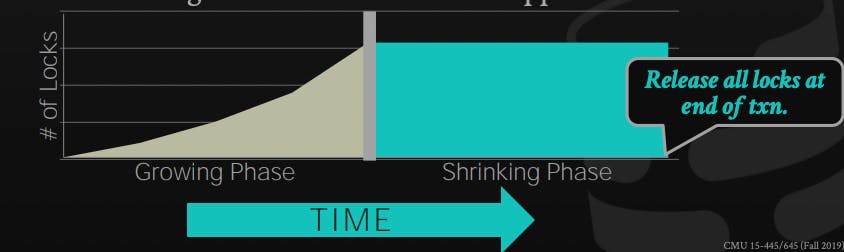
Phase 1: Growing
In this phase, the transaction is allowed to request the locks that it needs from the DBMS lock manager, it either gets the lock or gets a denial and waits for the lock to be granted
Phase 2: Shrinking
In this phase, the transaction is only allowed to release locks that it already owns, it's not allowed to request any new lock.
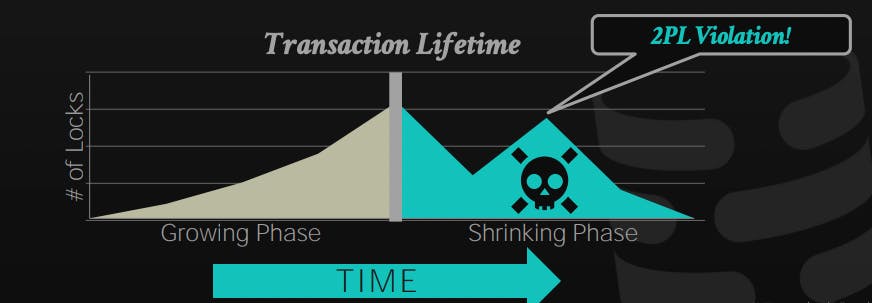
Let's discuss the same example but with 2PL applied:
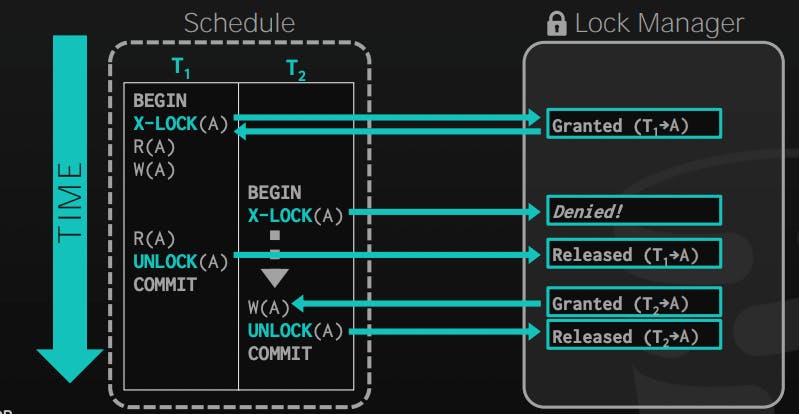
The major difference is that we didn't release the lock for A, and then request it again, as this violates the 2PL. By keeping the lock, we prevented T2 from getting a dirty read that has not been committed yet!
By obeying 2PL, we guarantee generating conflict serializable schedules, as the precedence graph of those schedules is acyclic. However, we introduced a new problem called cascading aborts. Transaction T2 may read a value that T1 changed previously, but then T1 aborts, which requires the DBMS to abort T2 as it got a value that should not have leaked outside.
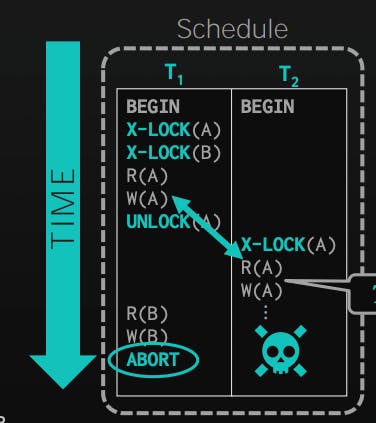
To solve this issue, we can use another variation of 2PL that requires releasing the locks only at the end of the transaction. This limits the concurrency for sure, but guarantees there are no dirty reads/ cascading aborts.
Lock Hierarchy
Why?
In the previous examples, we assumed that we are locking each tuple with a single lock, however, this is not efficient in real-world, because sometimes we want to lock the whole table.
Assume we are running a transaction to update the whole bank accounts to get 10% interest each year, it would be like this:
BEGIN TRANSACTION;
SELECT * FROM Accounts;
UPDATE Accounts SET balance = balance * 1.1
COMMIT;
If we have 1 billion rows, we are going to request 1 billion locks for this query will pollute the DBMS lock manager with a huge amount of wasted memory.
How?
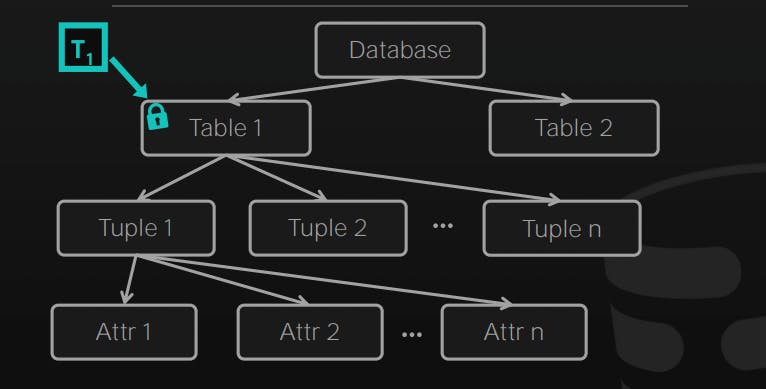
Locks are organized in a tree-like structure, where each node represents a database object, and the parent node represents a higher level of granularity than its children. For example, the root node of the lock hierarchy could represent an entire database, while its children nodes represent individual tables within the database. The children of a table node could represent individual rows within the table.
When a transaction wants to access a database object, it must first acquire a lock at the appropriate level of granularity. For example, if a transaction wants to update a row in a table, it must first acquire a lock on the table. If another transaction wants to update a different row in the same table, it must also acquire a lock on the table.
Using intention locks to allow a higher level nodes to be locked in either shared or exclusive mode, without having to check all the descendent nodes.

To get an S or IS lock on a node, the transaction must hold an IS lock on the parent node.
To get an X, IX, or SIX on a node, the transaction must hold an IX lock on the parent node.
Example:
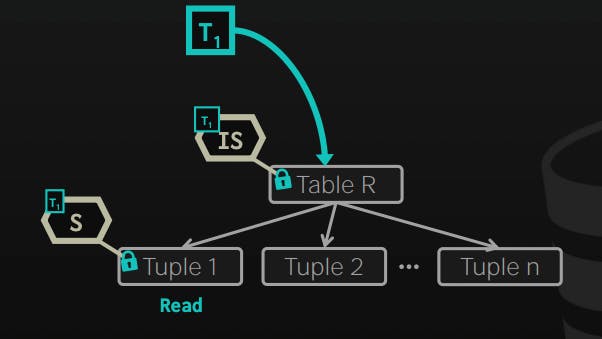
It is worth noting that usually, it's the mission of the DBMS to maintain those locks, and in rare cases, the developer might need to use explicit locks on the transaction to give hints to the DB to improve performance.
References
CMU15-445/645 Database Systems lecture notes. Retrieved from: 15445.courses.cs.cmu.edu/fall2019
Note: ChatGPT was used to help me refine and make this post more concise, and readable, and provided some examples. So huge thanks to OpenAI!