



Introduction
Different applications have different requirements, as discussed in What the heck is OLTP, OLAP?, it depends on business rules to define the workload of our database. Therefore, we need different storage models for the database in order to fulfill those workloads while maximizing the utilization of I/O and storage.
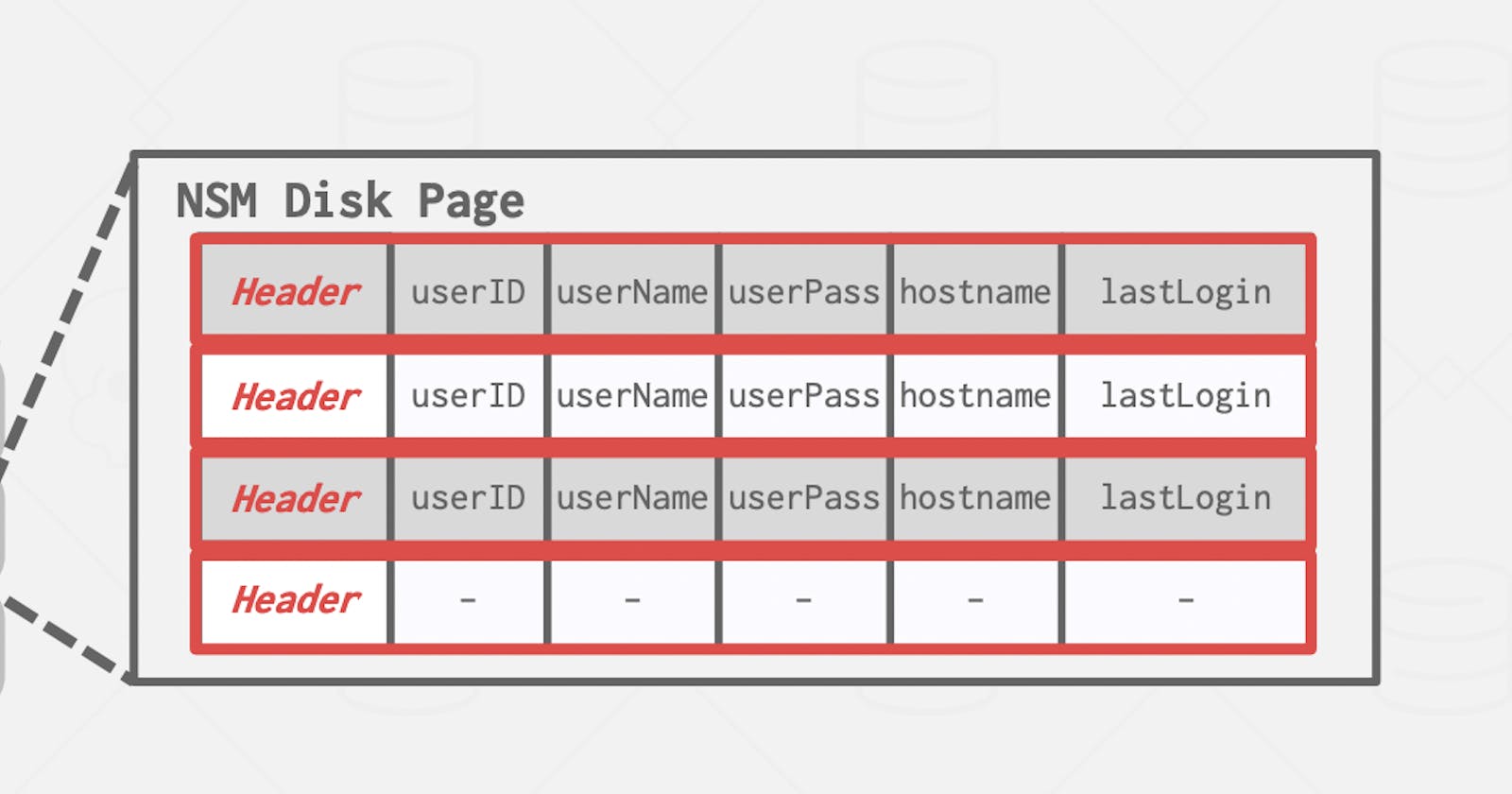
N-Ary Storage Model (NSM)
In this model, the database stores the attributes of a single record contiguously on a page (in some cases there might be overflow). Which makes it better for OLTP workloads, as it is easy to insert a new record, or modify an existing one. Also, retrieving the whole record is not a big deal in this case, because it's stored contiguously, retrieving the page results in having all attributes. This model is used in row-store databases.

Advantages:-
- Fast insertion, updates, deletes
- Reduce I/O in case of retrieving the whole record (all of its attributes or most of it)
Disadvantages:-
- Not suitable if we want to select a specific attribute or do a query using a specific attribute (we can use indexes to overcome this problem)
- We can't do real compression because every attribute might have a different type than the next one
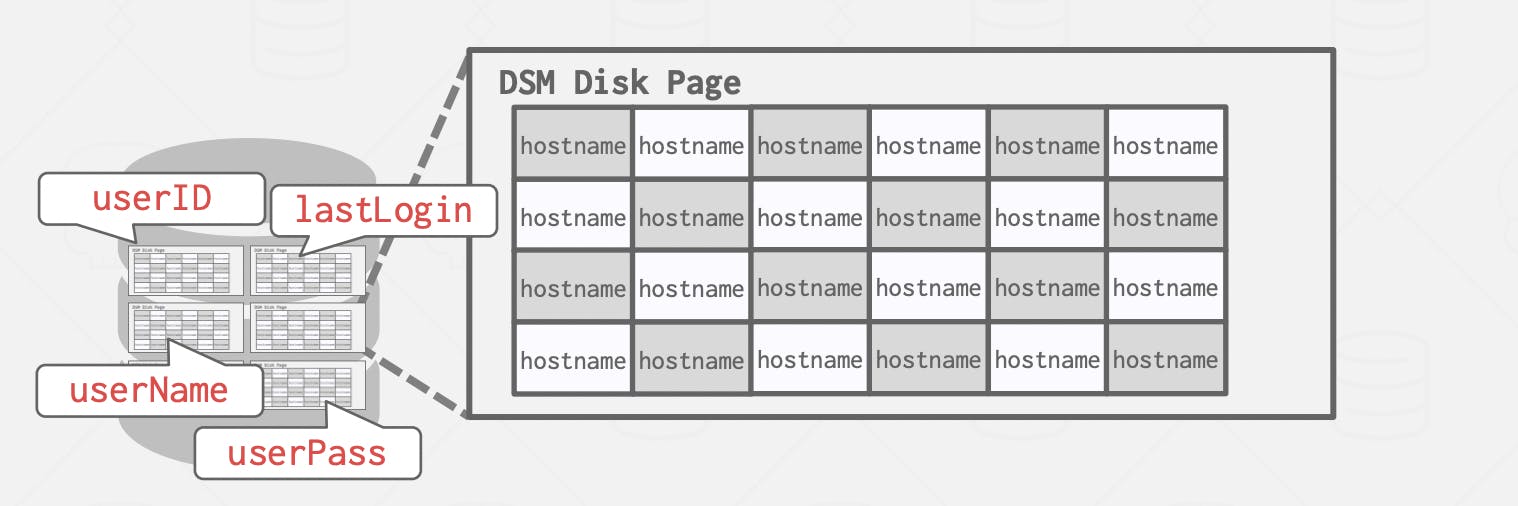
Decomposition Storage Model (DSM)
In this model, the database stores a single attribute contiguously on a page. which makes it ideal for OLAP workloads that require complex queries done on specific attributes, to do the filtering, the engine retrieves those attribute values easily because they are stored on the same pages contiguously, there's no waste of I/O to retrieve attributes that are not going to be used. It's suitable for heavy read applications.
Advantages:-
- Less I/O because we only read attributes that are related to the query
- Opens the door for compression, because the same types are always stored within the same pages.
Disadvantages:-
- More complicated insert/update/delete queries, as it requires more I/O to reach different attribute pages.
References
- CMU15-445/645 Database Systems lecture notes. Retrieved from: 15445.courses.cs.cmu.edu/fall2022
- Database Internals: A Deep Dive into How Distributed Data Systems Work 1st Edition