



Introduction
Our real-world run concurrently, which means that there are many things that happen at the same time. For example, you are reading this blog post while your friend is driving, or maybe he is just sleeping! The fact that you are doing something shouldn't prevent another one from doing his own task.
It may seem that concurrency is just another fancy word to say parallelism, however, there's a major difference between them. Parallelism is to perform more than one task at the same time. However, concurrency means that we allow many tasks to make progress with each other. The same reason is what makes multiprocessing different from multiprogramming. Multiprocessing means run in parallel, however, multiprogramming means run concurrently.
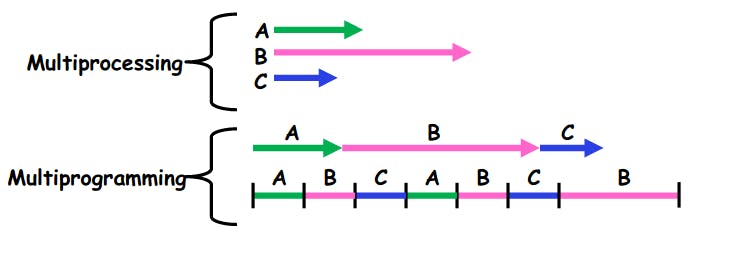 Difference between multiprocessing and multiprogramming. Retrieved from: cs162.org
Difference between multiprocessing and multiprogramming. Retrieved from: cs162.org
As usual, engineers love to use patterns from real-life to solve their engineering problems. So, they created Threads!
Programming before threads
Each process was sequentially executed, and there's no notion of concurrency without creating another process, we can not listen for keystrokes and fetch the data from the same process. Why don't we just create as many processes as much as we need? By this, we can also utilize the multicores that hardware designers gave to us. While this has been used for a while, it makes it very hard to create communication between processes. Also, the context switch between processes is high because we need to maintain our isolation between processes while we are adding this context switch operation. Suppose a web-browser needs to fetch data and parse it, also listen for the keystrokes, it may create each process for each task. Suppose that the fetching process needs to tell the browser it's done, it needs to use one of the interprocess communications methods that we created, which is hard, and overwhelm our operating system with too many tasks to provide memory protection and isolation! We need a better way!
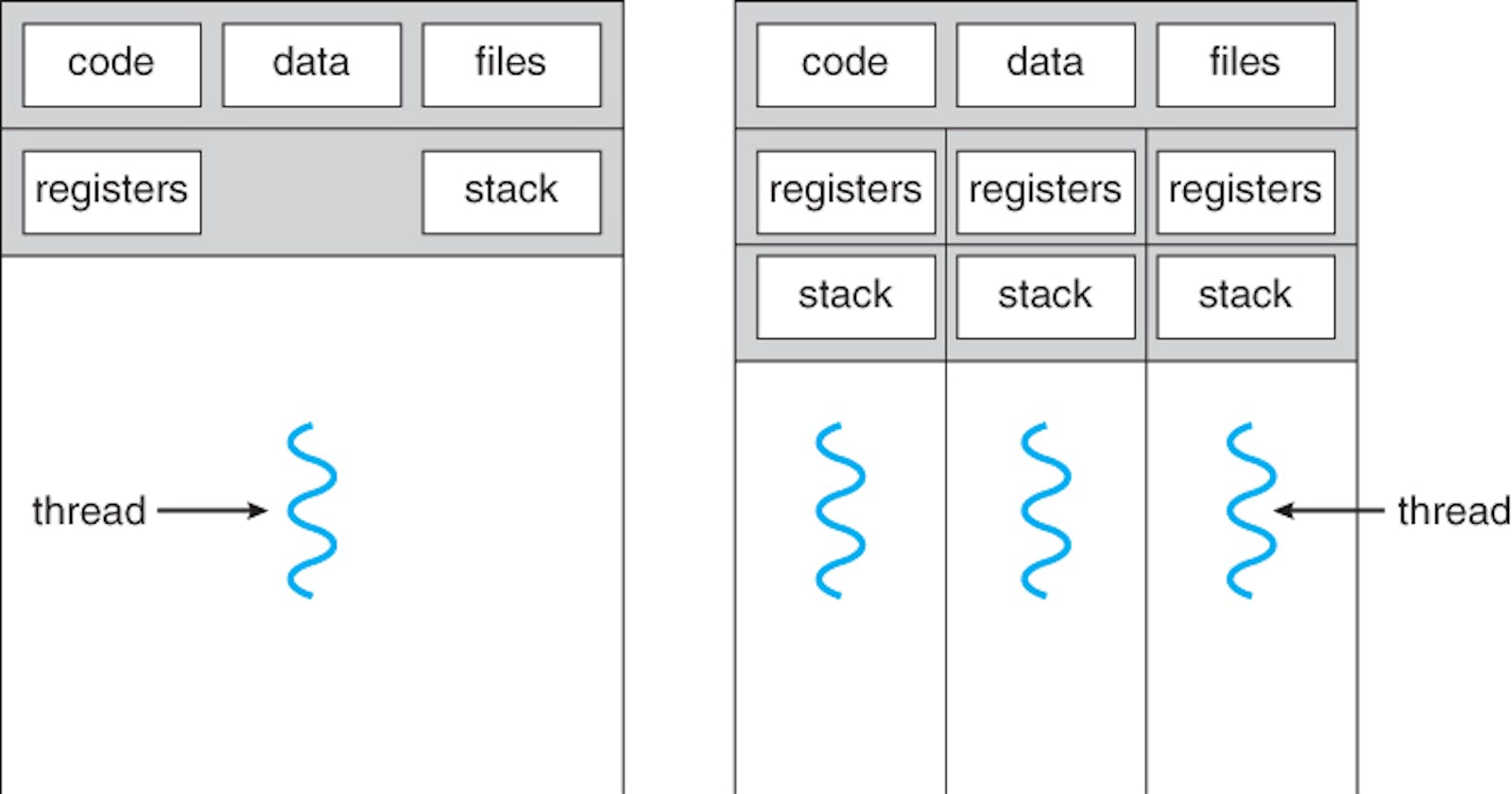
In order to reduce the overhead of processes context switching alongside enabling concurrent tasks to communicate in an easy way, why not to share some memory between these tasks? As we know, each process memory has code, global data, files, registers, stack, and heap. As we can see, code, global data, files, and the heap are the same between all the concurrent tasks. However, we can not share the stack or the registers!
Sharing the stack means that we don't know where to go after we return from this function, or which local data belongs to which task! Also, sharing the registers makes it impossible for the CPU to give us the correct results of our computations!
Thread Abstraction
A thread is a set of sequential streams of execution that interact and share results easily. We can gather multiple threads to do multiple tasks inside the same process. This enables us to communicate in an easier way and to reduce the cost of context switching. The main concepts behind creating threads are:
If we share some memory regions, we can communicate in easier ways than before
Allow each task to create an I/O request without stopping all the process tasks!
Each thread shares the heap, global data, and the code with all other threads running in the same process. However, each thread has its own stack and registers. By having the same heap, threads can talk to each other, and by having different stacks, we can run functions safely and keep sure that each thread will return to the caller, and separate registers to help the CPU do its job!
Multithreading Madness
When running concurrent threads, in some situations we may need to predict the speed of each thread. However, the speed of thread execution is totally unpredictable, that's because the operating system is virtualizing the CPU for us and we don't know when it will execute each thread. Suppose that we have a simple computation that we run in a single-threaded process. As a programmer, we may think the processor will execute each step after the other. However, because we are running with other processes in the same operating system, the operating system is scheduling each thread to run by its own algorithms.
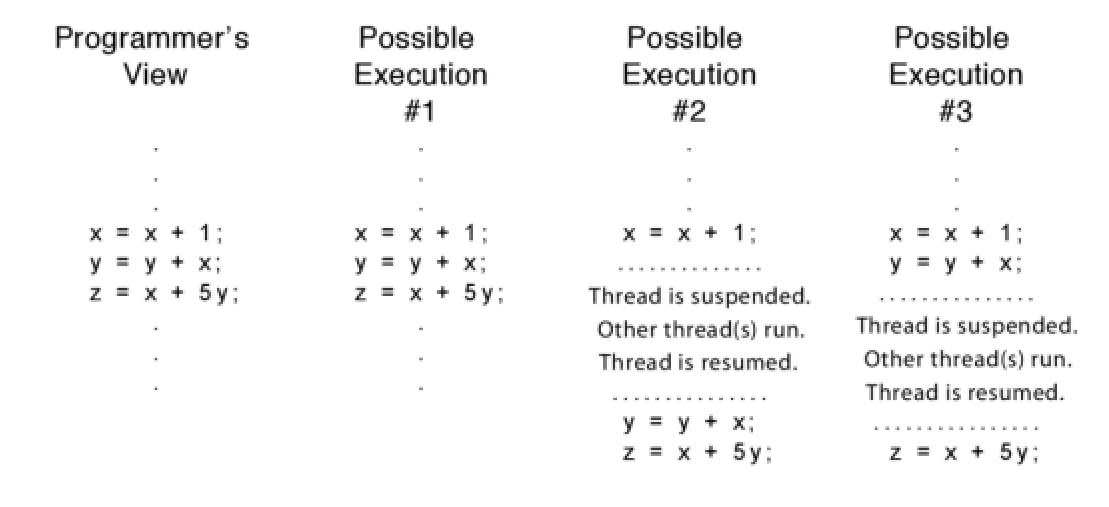 Different possible ways of a single-threaded process. Retrieved from: Operating Systems: Principles & Practice
Different possible ways of a single-threaded process. Retrieved from: Operating Systems: Principles & Practice
This strange behaviour happens all the time, as we said, we are sharing the CPU with other processes. That's why the multithreading paradigm is more complicated than the single-threaded one. We will discuss how to overcome these complexities soon.
Conclusion
Concurrency doesn't mean parallelism, if we are running in a single-core machine, there's no way to execute two different instructions at the same time.
Multithreading is used to perform concurrent tasks (Multiprogramming) just like how real-world does.
Thread context switching is much cheaper operation than process switching because we only change stack pointer and registers.
Threads can communicate in a much easier way than processes.
Threads execution speed can not be determined, and we should not design a system depending on the speed of each thread.
References:
- Anderson, T., & Dahlin, M. (2014). Operating systems: Principles & Practice.